

Ostatnio miałam okazję tworzyć konfigurację projektu dla KNI Kernel. Maly zespół, kilka osób, Open Source, Vue na froncie, Firebase jako baza i backend (BaaS). Podeszłam do tego jako programista zaznajomiony przynajmniej z częścią dobrych praktyk, piszący kod komercyjny. I gdy tak zaczęłam powoli stawiać repozytorium, narzędzie do CI/CD, konfigurować testy… to zdałam sobie sprawę, że dla początkującego programisty nie są to rzeczy oczywiste. Z kilku nauczyłam się korzystać dopiero w pracy. A oprócz tego, że ułatwiają życie, to pojawiają się w ogłoszeniach o pracę i w czasie rozmów kwalifikacyjnych. Dodajmy do tego gorącą dyskusję na jednej z grup na Facebooku.
Tematem dzisiejszego postu są praktyki, które powinny się znaleźć w każdym komercyjnym projekcie, a jeśli trafiłeś do firmy, która się nimi nie przejmuje – tak całkiem szczerze – uciekaj stamtąd.
Jest to także zbiór pojęć, które mogą przydać się juniorowi w trakcie rozmowy kwalifikacyjnej. Jeśli zauważysz błąd lub uważasz, że czegoś brakuje, daj mi znać w komentarzu!
Dopiero się uczę, nie muszę tego znać!
Owszem, nie musisz, kiedyś poznasz. Dobrych praktyk najlepiej uczyć się jak najwcześniej. Poza tym, jak się przekonasz, idzie za nimi wygoda. Ja ich używam, bo jestem leniem, serio. I dla mnie jest to minimum konfiguracji z kilkoma użytecznymi dodatkami.
Elementy konfiguracji projektu
Stworzyłam poniższą listę przy okazji spisywania, co muszę skonfigurować do wspomnianego projektu dla Kernela. W ten sposób powstał podstawowy setup Spektrum, projektu, który sam sprawdza czy działa i bije po łapach członków zespołu developerskiego (czyt. krzyczy na Slacku na czerwono Build Error job failed), jeśli jest inaczej.
1. Repozytorium
Absolutne minimum. Podstawa podstaw. Obojętnie, czy robisz projekt solo, czy w zespole. System kontroli wersji pozwala ci na… tworzenie wersji. Cofanie zmian, łatwy podział pracy, możliwość przechowywania zmian zdalnie… Czy naprawdę muszę to pisać? Znajomość systemu kontroli wersji to obecnie must-have dla każdego juniora. Obecnie najpopularniejszy jest Git. Z innych spotkałam się w firmach jeszcze z SVN-em i Mercurialem. W rzeczywistości jest ich dużo więcej, wystarczy zerknąć do Wikipedii.
Dlaczego git? Jest stosunkowo prosty w obsłudze: w projektach solo dostajemy wspominaną możliwość łatwego cofnięcia zmian, w projektach zespołowych mogą pomóc tzw. gałęzie (branche) – każdy członek zespołu pracuje sobie na swojej gałęzi, co jakiś czas dodając swoje zmiany do gałęzi głównej (dev/master), dzięki czemu nie nadpisują sobie nawzajem zmian. To tak w skrócie.
Trzymanie kodu na Dysku Google nie jest dobrym rozwiązaniem. Uwierz mi – been there, done that
I oczywiście, ze zdalnych serwerów umożliwiających hosting kodu najpopularniejsze są Github (tutaj Dominika opisuje kontrowersje po przejęciu go przez Microsoft), Bitbucket i Gitlab. Zdarzyło mi się korzystać jeszcze z Azure DevOps (kiedyś VSTS).
Pamiętaj o bezpieczeństwie
Zanim umieścisz swój kod w zdalnym repozytorium, zadbaj o to, aby usunąć z niego tokeny i hasła. Jeśli ktoś będzie chciał skorzystać z twojego kodu, wygeneruje je sobie sam, po co ma używać twoich?
Przykładowo: mam w projekcie plik env.local, który zawiera konfigurację do Firebase. Dodaję go do .gitignore, a na Githuba wrzucam plik bez wrażliwej konfiguracji, za to o nazwie env.local.example.
Readme
Readme to plik, w którym możemy opisać swój projekt. Można tam zamieścić skróconą instrukcję obsługi i uruchomienia, opis poszczególnych części projektu albo wrzucić badge :) Czasami dostajemy je od razu wygenerowane (np. przy tworzeniu projektu z pomocą Vue CLI), ale niekiedy musimy wygenerować je sobie sami. W projekcie to must-have. To informacja nie tylko dla rekrutera, który przegląda nasze portfolio, ale dla każdego, który chciałby użyć kodu.
Readme można pisać w wielu językach, najbardziej lubię Markdown (ciekawostka: przed wejściem edytora Gutenberg wszystkie posty na BC były pisane w Markdownie).
Licencja
Licencja mówi, co potencjalny użytkownik/kontrybutor może zrobić z kodem. Jeśli chcesz stworzyć projekt Open Source, warto zadbać o poprawną licencję. W projektach prywatnych najczęściej używam licencji MIT. Pozwalam innym używać mojego kodu, jak tylko chcą, pod warunkiem że umieszczą u siebie informację o prawach autorskich.
Licencji jest naprawdę wiele i są tematem na osobną serię postów (najlepiej pisaną przez kogoś z doświadczeniem w temacie ochrony własności intelektualnej), ale całkiem dobrze podsumowują je autorzy TLDRLegal.
Posprzątaj przed pushem
Gdy kodzimy, budujemy nasz projekt. Tworzymy plik wykonywalny, archiwum JAR, ZIP lub minifikujemy nasz kod. Takie pliki nie powinny znaleźć się w repozytorium. Powodów jest kilka: są to artefakty, które jesteśmy w stanie łatwo wygenerować z kodu, zajmują niepotrzebnie miejsce w repo, a w przypadku plików binarnych kiepsko się wersjonują. Tak samo z zewnętrznymi bibliotekami/frameworkami. Nimi zajmują się narzędzia do dependencji (NPM, Yarn, Maven, Gradle, pip i inne). Doceniam, że chcesz mieć 2000 nowych linijek w tym commicie, ale niech to będzie kod twojego autorstwa, nie zbundlowane i zminifikowane node_modules.
Foldery z plikami wykonywalnymi i dependencjami powinny znaleźć się w .gitignore.
2. Zaplanuj zadania
W większych projektach warto sobie rozpisać podstawowe funkcjonalności na zadania. Można skorzystać z wielu narzędzi: Pivotal Tracker, YouTrack, GitKraken Glo czy Trello to tylko niektóre z nich. Osobiście wolę Github Project Boards.
Tworząc zadania, nie zapomnisz co chciałeś dodać do projektu i łatwiej zaplanujesz pracę. Przy okazji możesz pobawić się z integracją narzędzia do zadań z repozytorium. Wtedy każde zadanie zasługuje na osobnego brancha i po wciągnięciu na branch główny (develop/master) jest automatycznie zamykane. O takiej integracji Githuba z Trello można przeczytać tutaj.
Samo rozpisanie zadań to dopiero wierzchołek góry lodowej, ale w ten sposób określasz kierunek, w którym chcesz podążać i możesz lepiej kontrolować swoją pracę.
3. Dokumentacja
Dokumentacja to bardzo szerokie pojęcie i chciałabym w tym punkcie zawęzić je wyłącznie do dokumentacji w kodzie. W tym znaczeniu dokumentacją są specjalnie formatowane komentarze umieszczone przed blokiem kodu, które opisują, co w tym bloku kodu siedzi.
Wchodzimy w tym momencie w pojęcie samodokumentującego się kodu. Oznacza ono kod czytelny, z opisowymi nazwami zmiennych i funkcji, tak, aby nie było wątpliwości co do ich przeznaczenia. I w ten sposób zamiast:
// average height
var AH = 160;
Możemy napisać czytelniej i bez potrzeby komentowania:
var AVERAGE_HEIGHT = 160;
Komentarze przydają się w momencie, gdy chcemy wyjaśnić jak coś działa, zamiast co robi. Wytłumaczyć się z jakiegoś nieeleganckiego rozwiązania, wyjaśnić niedopowiedzenia czy opisać, co właściwie w tym bloku kodu się dzieje albo dlaczego tak. Przykład? Z repozytorium vue.js:
if (navigator.userAgent.indexOf('PhantomJS') > -1) {
// use mocks in e2e to avoid dependency on network / authentication
setTimeout(function () {
self.commits = window.MOCKS[self.currentBranch]
}, 0)
}
Co się tutaj dzieje? Twórcy Vue tłumaczą, że w tym miejscu w przykładzie używane są zamockowane dane, ale w testach end2end. Wyjaśniają swoje intencje, które mogły być niejasne.
Ale dość o samych komentarzach, wróćmy do generowania z nich dokumentacji. Jesteśmy przy JSie, więc użyję go jako przykładu. Pewnie znasz typowy komentarz blokowy w JS:
/*
This is commented
*/
A tak wygląda tzw. documentation comment:
/**
* This is documented
* @param obj function param
*/
Taki dokumentujący komentarz blokowy możemy potem zeskanować odpowiednim narzędziem (JSDoc dla JavaScriptu, JavaDoc dla Javy, Doxygen w C++, pydoc, Sphinx dla Pythona, itd.) i wygenerować dokumentację w formie strony WWW (którą możemy potem umieścić np. na Github Pages). Przykład z jednego z moich projektów, projekt w Vue udokumentowany z pomocą JSDoca:

Jak ma się to do idei samodokumentującego się kodu? Wrzucasz w komentarze dokumentujące to, co chcesz, aby zostało sformatowane. Masz do dyspozycji wiele makr (jak użyte powyżej @param), które na przykład pozwalają oznaczyć specjalne bloki (moduł, funkcja, konstruktor) czy parametry wejścia i wyjścia.
Co jeśli chcesz stworzyć dokumentację taką jak przewodnik po Vue? Możesz użyć generatorów stron, takich jak Jekyll, VuePress, Nuxt czy Docsify.
Nawet jeśli nie chcesz bawić się w dokumentację, warto chociaż wiedzieć, że coś takiego istnieje i znać pojęcie documentation comment.
4. Testy
Kolejne must-have. Testy są nie tylko po to, aby użytkownicy otrzymali jak najlepiej działający produkt. Są też dla ciebie – wyłapią twoje błędy. Zależy ci na pisaniu dobrego kodu? Udowodnij to testami! Wymówka U mnie działa przestaje mieć wtedy znaczenie.
Testów jest też wiele rodzajów (na przykład podział na testy biało- i czarnoskrzynkowe). Uwzględnia się również poziomy testów:
- jednostkowe (weryfikacja poszczególnych części – jednostek – programu)
- integracyjne (weryfikacja integracji poszczególnych komponentów)
- systemowe (weryfikacja zachowania całego systemu)
- akceptacyjne (wykonane w celu uzyskania akceptacji co do jakości wykonanego oprogramowania, w tym testy alfa i beta)
Na pewno warto na początek zainteresować się testami jednostkowymi. Programista testy powinien pisać sobie sam, a prywatne projekty to idealny moment, żeby zacząć.
Frameworkami do testów jednostkowych w poszczególnych językach są przykładowo:
- Java: jUnit
- JavaScript: Mocha+Karma, Jest
- Python: pytest
- C++: CPPUnit, Google Test
Czy chcesz dodać coś do listy?
Idealną wersją tego punktu jest TDD, czyli Test Driven Development.
5. Pokrycie testami
Skoro mówimy już o testach, to ile powinniśmy ich napisać? I skąd wiemy, że pokrywają wszystkie funkcjonalności? Do tego służy miara nazywana pokryciem kodu testami (test coverage). W zależności od źródła istnieją różne kryteria pokrycia. Jeśli tworzymy raporty przy pomocy Jesta, możemy mówić o następujących kryteriach:
- function coverage – czy w testach wywołana została każda funkcja obecna w kodzie
- statement coverage – czy w testach została wykonana każda instrukcja obecna w kodzie
- branch coverage – czy testy uwzględniają wszystkie rozgałęzienia (np. spowodowane instrukcjami warunkowymi)
- line coverage – czy testy pokrywają wszystkie linijki kodu
Przykładowy raport z początkowej konfiguracji Spektrum, wygenerowany przy pomocy Jesta, wygląda następująco:
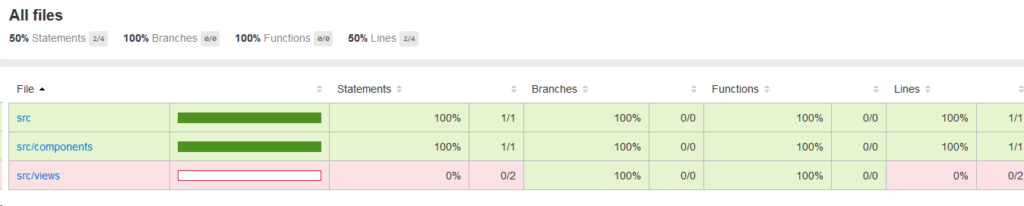
Raporty możemy też publikować w Internecie na platformie CodeCov. Tak prezentuje się tam powyższy raport.
6. CI/CD
Kolejny temat rzeka, który zasługuje na osobny post. Na temat aspektów CI/CD od strony devopsowej Dominika przygotowuje oddzielny wpis. Na razie przejdźmy do zagadnień ogólnych.
Czym jest CI/CD?
W dużym uproszczeniu: mówiąc o CI/CD, mówimy o pewnym zbiorze praktyk, które umożliwiają szybkie i sprawne dostarczanie aplikacji użytkownikowi. Chcemy zautomatyzować cały proces tworzenia, testowania i dostarczania oprogramowania. Przy czym CI, czyli Continous Integration oznacza, że chcemy mieć ciągłą integrację – wszystkie części naszej aplikacji mają przy każdej zmianie iść w to samo miejsce oraz przechodzić przez takie same procesy (np. testy). Z kolei CD oznacza Continous Deployment, czyli zautomatyzowane wrzucanie zbudowanego artefaktu w miejsce docelowe, często razem z budowaniem całego środowiska.
W praktyce…
W dużych projektach oznacza to automatyczne dowożenie kodu na produkcję. Kod pobierany jest z repozytorium, testowany, po spełnieniu odpowiednich warunków promowany do kolejnego etapu. CI/CD pozwala na kontrolę zależności pomiędzy poszczególnymi środowiskami, łatwe wrzucenie nowej wersji lub cofnięcie się do starej.
W małych projektach? Cóż, wspominałam, że jestem leniem. Zapinam CI/CD, bo jako programista chcę zajmować się programowaniem. Nie chcę stawiać środowiska, przerzucać plików przez FTP lub CLI na odpowiedni hosting, tworzyć artefaktów, chcę, aby mój kod robił to sam. I chcę być poinformowana natychmiast, jeśli coś nie działa.
Jak to wygląda w Spektrum? Po każdym wrzuceniu na repozytorium nowej wersji uruchamiane są testy (CI), a ich wyniki (i pokrycie) publikowane (i spięte ze Slackiem, stąd wspomniane bicie po łapach), a po włączeniu do gałęzi głównej (patrz punkt 1) również wykonywało deployment na środowisko docelowe, czyli Firebase (CD). Wszystko automatycznie, poza początkową konfiguracją i ewentualnymi poprawkami nie muszę robić nic. Został mi kod z testami do pisania.
Jeśli chodzi o narzędzia, to z pewnością zaliczają się do nich:
- Jenkins
- Travis
- CircleCI
- AppVeyor
- Buddy
- Gitlab (repozytorium + narzędzie do tasków + artefakty + CI)

- Azure DevOps (jak wyżej)
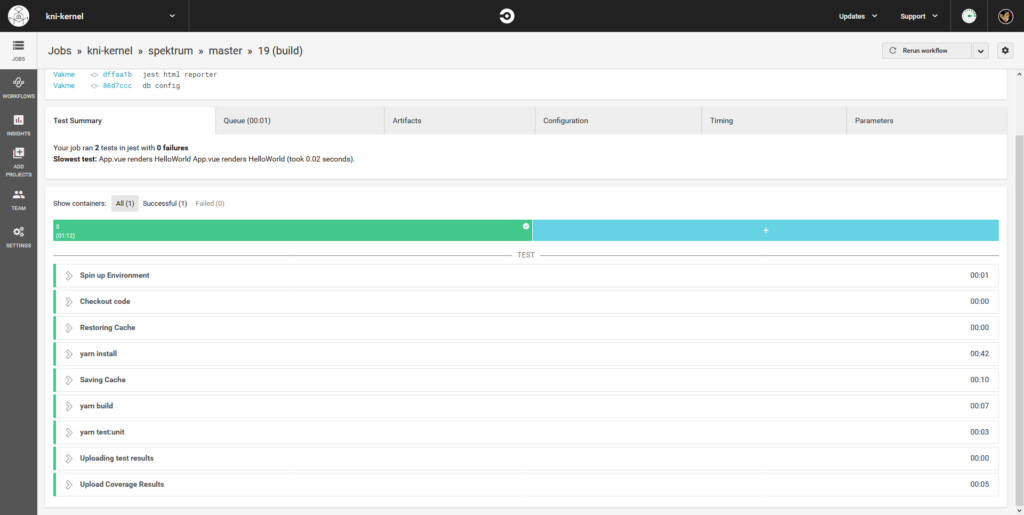
W jaki sposób działa narzędzie do CI? Pokażę na przykładzie CircleCI, którego używam w Spektrum. Oczywiście, w zależności od narzędzia, sposób konfiguracji się różni.
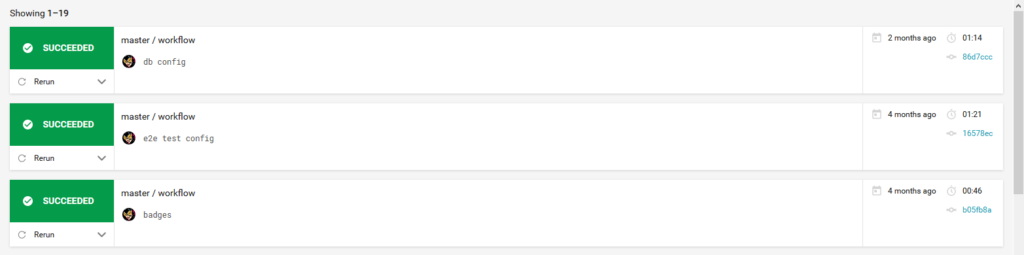
- W panelu CircleCI dodałam repozytorium z projektem
- Do repozytorium wrzuciłam plik
config.ymlz opisanymi poszczególnymi krokami, które narzędzie ma wykonać - Wykonałam push na githuba
Et voilà! CircleCI automatycznie zaciągnął do siebie repozytorium i wykonał poszczególne kroki.
Jeśli chcecie wiedzieć więcej, to niedawno na Devstyle odbył się tydzień z Continuous Integration.
Podsumowanie
Ten post powstawał bardzo długo – kilka miesięcy. Długo wahałam się, w jaki sposób skondensować w nim jak najwięcej użytecznych pojęć i przykładów, jednocześnie bez zagłębiania się w szczegóły.
Każdy z poruszonych sześciu punktów to zaledwie ułamek wiedzy, jaką może (i powinien) posiadać dobry programista. Każdy z tych punktów można rozwinąć w osobnym poście (a nawet serii postów).
Jeśli uważacie, że czegoś tutaj brakuje, dajcie mi znać. Tymczasem miłej zabawy przedstawionymi narzędziami i do następnego!
Dodaj komentarz